
目前预测批次生产周期的统计方法平均只能达到 70% 的准确率,对于希望提高生产效率、产线忙碌的晶圆厂而言,该准确度无法满足其需求。最终,由于统计模型无法体现晶圆厂的实时生产动态,因此晶圆厂的团队每天都要花费大量时间核查预测数据,并重新进行预测以获得准确的数据。这表明晶圆厂需要采用一种更快速、简单、准确的解决方案来预测每 14 天为一周期的批次生产周期。在最近的一个客户应用中,SmartFactory AI Productivity 解决方案和 Engineered Works™ 被证明可以将生产预测的准确率提高到 85%。
通过一些实验研究,我们确定最适合该客户需求的ML 模型是基于梯度提升树的机器学习模型,特别是基于轻量梯度提升机的模型部署。该框架在行业中已得到广泛应用。由于该框架用于对表格数据进行预测,对未知数据具有很强的生成属性,同时抗噪声能力強,因此非常适合该客户。
借助 SmartFactory AI Productivity解决方案,根据之前 24 个月的工厂数据,我们对 ML 模型进行了训练。对于特征计算,我们定义了多个可表示批次流程和晶圆厂生产行为的特征,例如工作站统计数据和 WIP(在制品)特征,我们每天都会根据批次优先级,并针对每个路线或部件的站点对这些特征进行计算。我们使用 Clickhouse 数据库来存储特征数据。
该 ML 模型建立在当前工作系统之上,因此该 ML 模块和当前 RTD 或排程解决方案可相互协作和通信。该 ML 模型已被训练为可基于排程(包括每小时、每天或按班次)运行,并且已学习了从任一站点到最终站点的批次流程和当前晶圆厂生产行为。它将为每个站点创建一个模型,以预测最终站点的生产周期。例如,如果在站点 A 有一个批次,并且在生产完成之前还有 12 个站点,则将生成 12 个模型,一个模型对应一个站点,以预测到最后一个站点的生产周期。每个模型都将接受各项训练,包括历史特征数据、从当前站点到最终站点的 WIP 概况、利用率、设备可用性和批次优先级。这些模型被保存在磁盘的 pickle 文件中,并聚合到一个主 pickle 文件中供 Formatter 程序使用。可将这些模型部署到生产中。图 1 显示了部署的详细信息和结果。
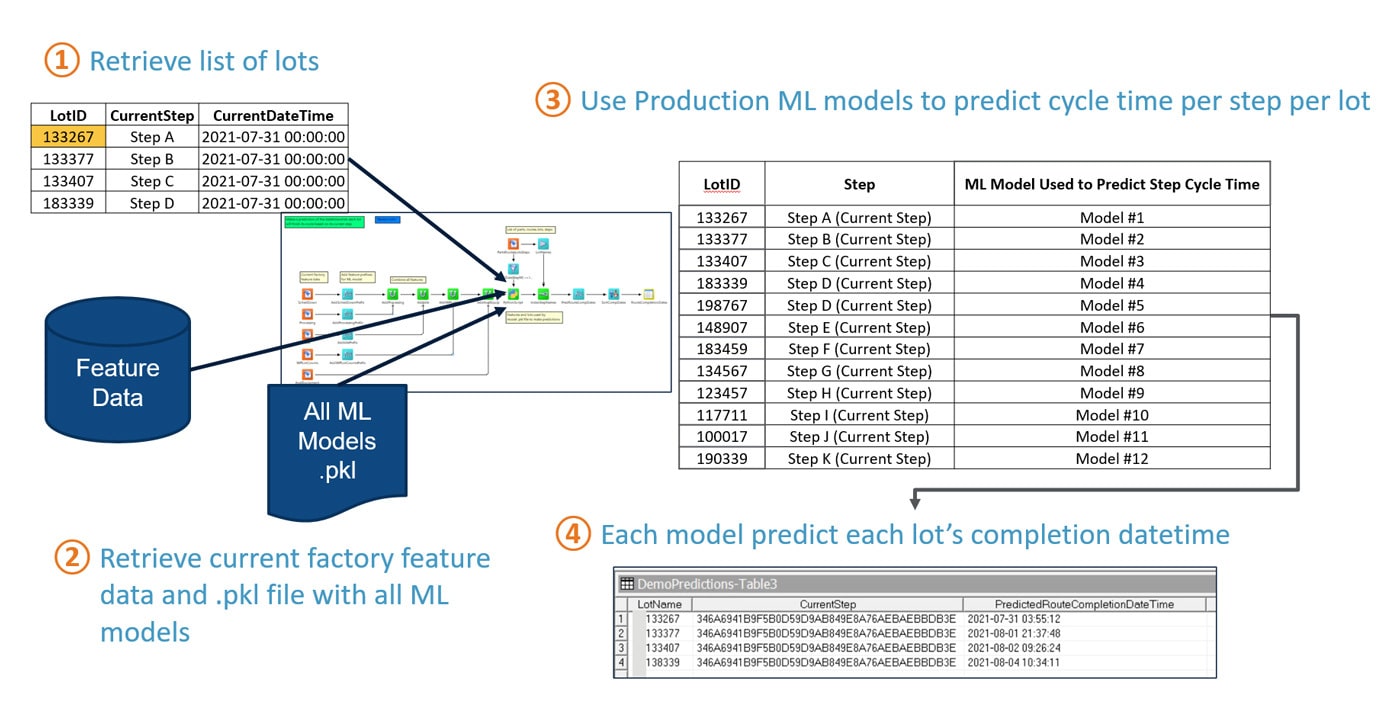
如当前 RTD 或排程解决方案系统需要某种预测,它会参考 ML 模块已经做出的预测。ML 模型可基于之前训练数据中未涵盖的条件自动重新训练,并会对预测做出修改,使结果更加准确。
有了准确的工厂生产预测模型,晶圆厂可以更好地确定造成批次延误的原因,提高订单交付速度,例如可通过更改派工规则参数来加快延迟批次的生产。
训练完成后,我们会基于测试数据集对面向客户开发的 ML 模型进行评估。我们对模型评估和准确性定义做出如下指标,并以此作为关键性能指标:均方根误差 (RMSE) 和平均绝对误差 (MAE)。我们将准确度指标定义为 1 平均绝对百分比误差,即每批次预测准确度的平均值。我们的准确性比较的结果显示,ML 模型的结果比基线模型要准确 5% 至 13%。准确性提高约 10% 可使按时交付率 (OTD) 提高 2%,库存维护成本降低 2%。
