
强化学习 (Reinforcement Learning) 已成为一种强大的技术,使算法能够通过自身的经验进行学习。作为一种机器学习方法,强化学习通过与环境交互来训练决策能力——系统接收“奖励”或“惩罚”的反馈信号,并不断优化长期累积奖励。
这项人工智能技术已为机器人、游戏开发和自动驾驶等领域带来革命性突破。本文将重点解析强化学习的核心优势,并论证其如何有效解决半导体制造在排程与派工环节中的关键性挑战。
工作原理
算法的目标是实现长期累积奖励最大化。对算法而言,“奖励”代表算法期望获得的行为或状态——即接近或达成预设目标的结果。例如,提升特定关键绩效指标 (KPI),或减少制程中的设备换线次数,均可设置为奖励条件。
同时,算法会从惩罚机制中学习。这些负向奖励标志着非期望行为或状态。当算法因某种行动导致不良结果时,惩罚信号会抑制其未来重复类似行为。通过这种反馈机制,系统能主动规避次优或错误的决策路径。
定义奖励与惩罚机制
为了更好地理解算法如何解读奖励与惩罚,我们可以参考以下示例(摘自我们的白皮书《用于半导体制造中 Q-time 管理的深度强化学习》):
在半导体制造中,队列时间约束 (Queue-time Constraints,简称 QTC) 规定了一个批次在连续工艺步骤之间的最大等待时长。若超出 QTC 限制,就会发生队列时间违规,进而导致良率损失(例如部件腐蚀)。如图1所示,生产线上的任意两个步骤之间都可能存在 QTC 限制。
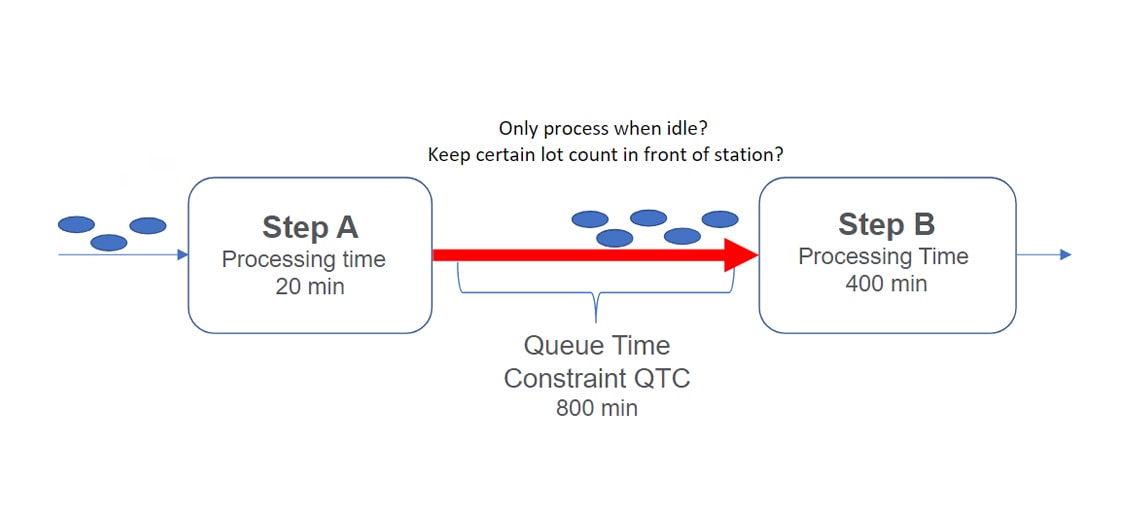
在这个示例中,我们的目标是构建一个强化学习算法,使其能够学习在队列时间约束下何时释放批次。算法会将“最小化队列时间违规”和“最大化产出”视为奖励信号,并持续采取能够实现这些目标的行动。而队列时间违规将作为惩罚信号,促使算法避免导致违规的操作步骤。
如需了解强化学习在实际应用中的另一个案例,请参阅《SmartFactory AI Productivity 可在更短时间内自动调整派工规则参数》。
以下是使用真实数据以这种方式带来的一些主要优势。
适应性
强化学习具备在动态环境中的适应与学习能力。与依赖假设的基于仿真的方法不同,强化学习可以直接从现实数据中学习,并有效应对复杂多变的情况。它通过实时交互学习并利用反馈优化决策,因此在动态环境中表现卓越。
对于排程与派工而言,这种适应性至关重要。新订单、设备故障以及其他各类突发事件都会影响排程与派工决策,此时强化学习快速适应的能力就显得尤为关键。此外,半导体制造涉及多设备协同、差异化处理时间及复杂工序依赖的精密工作流,进一步增加了复杂性。强化学习的动态调整力能使其能够理解并优化这些工作流,从而实现更高效的决策。
高效决策制定
在排程与派工中,自主决策能力(无需人工干预)对提升生产效率至关重要。传统半导体制造依赖多套派工规则和特定区域的排程来管理设备限制并优化生产流程。这些规则通常涉及多个参数,需要用户定期手动调整。
相比之下,强化学习通过在离线训练环境中学习最大化累积奖励,实现自主决策。通过“探索-利用”机制,强化学习算法能够自主学习并发现高效的运行策略,从而在实际生产环境中实现预期目标。强化学习算法能够自主适应并优化系统性能,无需依赖人工参数修改,显著减少频繁认为干预的需求,节省时间、人力和成本。
响应速度
实时排程与派工系统对制造运营至关重要,能够帮助产线满足时效性要求(如客户交付期限)。这类系统可有效识别生产瓶颈、平衡工作负载并优化资源配置,从而提升运营效率与整体产出。强化学习算法凭借其实时学习特性,能够快速适应并即时做出决策。这一优势使其能够及时响应环境变化,持续提升生产效率。
此外,强化学习具备迁移学习能力,可将从一个任务或环境获得的知识应用于其他场景。这一特性使算法能够基于既有经验快速建立专业能力。通过迁移已掌握的知识,当转换至不同派工区域时,强化学习可大幅缩短适应过程所需时间。
结论
强化学习技术展现出多方面的显著优势。其自主决策能力、实时学习特性和持续进化特点,使其成为极具发展前景的技术方向。随着这一人工智能方法的不断进步,其在解决实际半导体制造中复杂的排程与派工难题方面展现出巨大潜力。
通过应用强化学习算法,半导体制造商能够有效缩短生产周期、提升产出效率,并实现整体生产效能的持续优化。
FAQs
Why is data preparation for AI considered a challenge in semiconductor manufacturing?
Data preparation for AI can be expensive in terms of time and resources, making it a barrier, especially for smaller companies. Historical data may also be insufficient due to evolving environments.
How does simulation help overcome data collection challenges for AI deployment?
Simulation allows for the creation of synthetic data, eliminating the need for extensive data cleaning. It provides an efficient way to generate diverse and high-quality data for AI training.
What are some practical benefits of using simulation in AI deployment?
What role does simulation play in scenarios like Reinforcement Learning (RL) and Machine Learning (ML) in semiconductor manufacturing?
Simulation plays a crucial role in RL by providing a detailed environment for agents to learn and make decisions. In ML, it allows models to be trained on rich datasets, leading to operational efficiency gains and KPI comparisons.
