
Reinforcement Learning (RL) has emerged as a powerful technique that enables an algorithm to learn from its own experiences. RL is a machine learning approach where an algorithm learns to make decisions by interacting with an environment, receiving feedback in the form of rewards or penalties, and maximizing cumulative rewards over time.
This AI approach has revolutionized various fields, including robotics, gaming, and autonomous systems. Here, we will explore the strengths of RL and analyze its effectiveness in tackling critical challenges found in the scheduling and dispatching processes of semiconductor manufacturing.
How it works
The algorithm’s objective is to maximize the cumulative reward it receives over time. To the algorithm, a reward is a desired action or state—something that either is close to or achieves the RL’s goal. A rewarding outcome can be improving a particular KPI or limiting the number of setups in a process, for example.
The algorithm also learns from penalties it receives. These punishments, or negative rewards, are undesirable actions or states. Receiving an undesirable result discourages the algorithm from taking this type of action again. Punishments provide feedback to the algorithm, guiding it away from suboptimal or incorrect behavior.
Defining reward and penalties
To better understand how an algorithm views rewards and penalties, consider this example, (derived from our whitepaper, “Deep reinforcement learning (RL) for Queue-time management in semiconductor manufacturing”):
In semiconductor manufacturing, queue-time constraints (QTC) set the limit for how long a lot can wait between two process steps in its flow. Exceeding QTC results in queue-time violations that represent yield loss (i.e., corrosion of a part). Any pair of steps in a route can have a QTC between them, as seen in the example in figure 1, below.
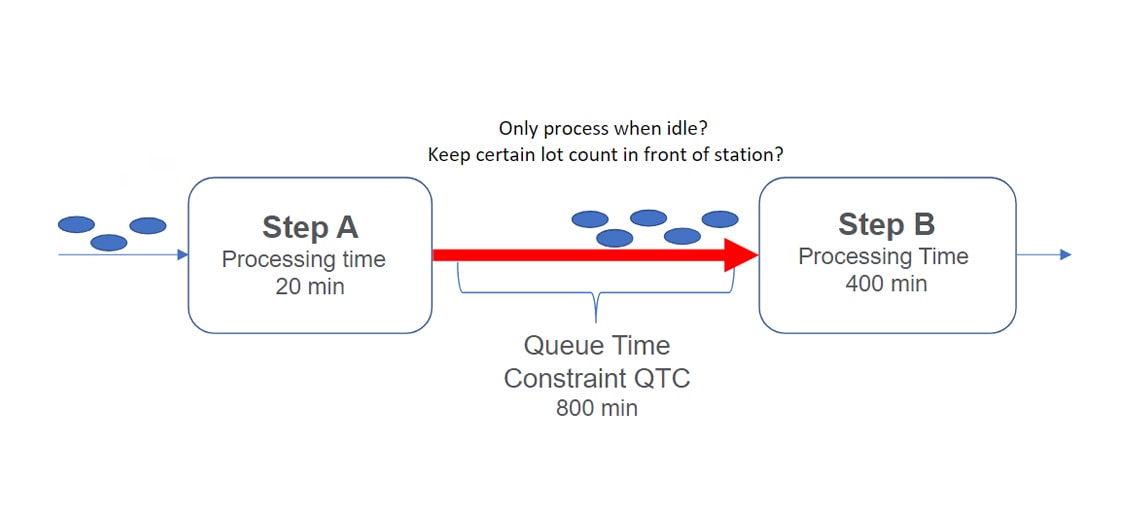
For our example, the goal would be to set up an RL algorithm to learn when to release lots in this QTC. The algorithm would see minimized que time violations and maximized throughput as a reward and would try to continue to take the actions that led to that. The penalty would be que time violations, so it would learn to avoid taking the steps that resulted in violations.
For another example of a practical application of RL, visit “SmartFactory AI™ Productivity tunes dispatching rule parameters automatically, in less time.”
The following are some of the many advantages to using real world data in this way.
Adaptability
RL offers adaptability and learning capabilities in a dynamic environment. Unlike simulation-based methods that rely on assumptions, RL can directly learn from real-world data and effectively handle complex and uncertain scenarios. It excels in active environments by learning from direct interactions and using feedback to improve its decision-making.
For scheduling and dispatching, this adaptability is crucial. With new orders, machine failures, and various other unexpected events impacting scheduling and dispatching decisions, RL’s ability to quickly adapt becomes essential. Moreover, semiconductor manufacturing involves intricate workflows with multiple machines, various processing times, and dependencies, adding to the complexity. RL’s capabilities to adjust allows it to understand and optimize these workflows, ensuring optimal decision making.
Optimal Decision-Making
Autonomous decision-making, independent of human intervention, plays a pivotal role in productivity for scheduling and dispatching. Traditionally, semiconductor facilities rely on multiple dispatching rules and schedulers specific to different areas to manage equipment constraints and optimize production flow. These rules often involve several parameters which require manual adjustments by users on a regular basis.
In contrast, RL enables autonomous decision-making by learning to maximize cumulative rewards in an offline training environment. Therefore, through exploration and exploitation, RL algorithms learn and uncover optimal strategies to achieve desired outcomes in an online production environment. Instead of relying on manual parameter adjustments, RL algorithms can autonomously adapt and optimize system performance. This reduces the need for frequent manual intervention, saving time, effort, and cost.
Speed
Real-time scheduling and dispatching systems are essential for manufacturing operations to meet time-sensitive requirements, such as customer delivery deadlines. Real-time systems facilitate the detection of bottlenecks, the distribution of workloads, and the effective allocation of resources, resulting in improved efficiency and increased throughput. RL algorithms, known for their real-time learning capabilities, adapt and make instantaneous decisions. This advantage empowers RL algorithms to promptly respond to a changing environment, ultimately maximizing productivity.
Furthermore, RL has the potential for transfer learning, allowing knowledge gained from one task or environment to be applied to another. This capability enables RL to leverage prior knowledge and start with a higher level of proficiency. By transferring learned knowledge, RL can accelerate the adaptation process when transitioning to different dispatching areas.
Conclusion
RL presents a multitude of benefits. Its capacity for autonomous decision-making, real-time learning abilities, and ongoing evolution makes it a promising approach. The continuous advancement of this AI approach holds immense potential for effectively addressing complex challenges in real-world semiconductor scheduling and dispatching scenarios.
By leveraging RL algorithms, semiconductor manufacturers can achieve a reduction in production lead times, an improvement in throughput, and an overall increase in productivity.
FAQs
Why is data preparation for AI considered a challenge in semiconductor manufacturing?
Data preparation for AI can be expensive in terms of time and resources, making it a barrier, especially for smaller companies. Historical data may also be insufficient due to evolving environments.
How does simulation help overcome data collection challenges for AI deployment?
Simulation allows for the creation of synthetic data, eliminating the need for extensive data cleaning. It provides an efficient way to generate diverse and high-quality data for AI training.
What are some practical benefits of using simulation in AI deployment?
What role does simulation play in scenarios like Reinforcement Learning (RL) and Machine Learning (ML) in semiconductor manufacturing?
Simulation plays a crucial role in RL by providing a detailed environment for agents to learn and make decisions. In ML, it allows models to be trained on rich datasets, leading to operational efficiency gains and KPI comparisons.

