
強化学習(RL)は、アルゴリズムが自らの経験から学習できる強力な手法として注目されています。RLは、アルゴリズムが環境とやり取りし、報酬やペナルティというフィードバックを受けながら、時間をかけて累積報酬を最大化することで最適な意思決定の方法を学ぶ機械学習手法です。
このAI手法は、ロボット工学、ゲーム、自律システムなど、さまざまな分野に革命的な変化をもたらしています。ここでは、RLの強みを探り、半導体製造におけるスケジュールとディスパチングプロセスで直面する重要な課題への取り組みにおける有効性を分析します。
仕組み
アルゴリズムの目的は、時間の経過とともに受け取る累積報酬を最大化することです。アルゴリズムにとって報酬とは、望ましい行動や状態(RLの目標に近いもの、または目標を達成するもの)を指します。例えば、特定のKPIを改善したり、プロセス内のセットアップ回数を制限したりすることが報酬となります。
同時にアルゴリズムは、受け取ったペナルティからも学習します。これらのペナルティ(または負の報酬)は、望ましくない行動や状態を示します。望ましくない結果を受けると、アルゴリズムは同じ行動を繰り返さないように学習します。ペナルティはアルゴリズムへのフィードバックとなり、最適でない行動や誤った動作を避けるよう誘導します。
報酬とペナルティの定義
アルゴリズムが報酬とペナルティをどのように扱うかを理解するために、次の例を見てみましょう(当社ホワイトペーパー「半導体製造におけるキュー時間管理のための深層強化学習(RL)」より抜粋)。
半導体製造では、キュー時間制約(QTC)がフロー内の2つのプロセスステップ間でロットが待機できる時間の上限を定めます。QTCを超えると、歩留まり損失(部品の腐食など)を起こすキュー時間違反が発生します。ルート内の任意のステップの組み合わせにQTCを設定することができ、図1の例にその設定方法が示されています。
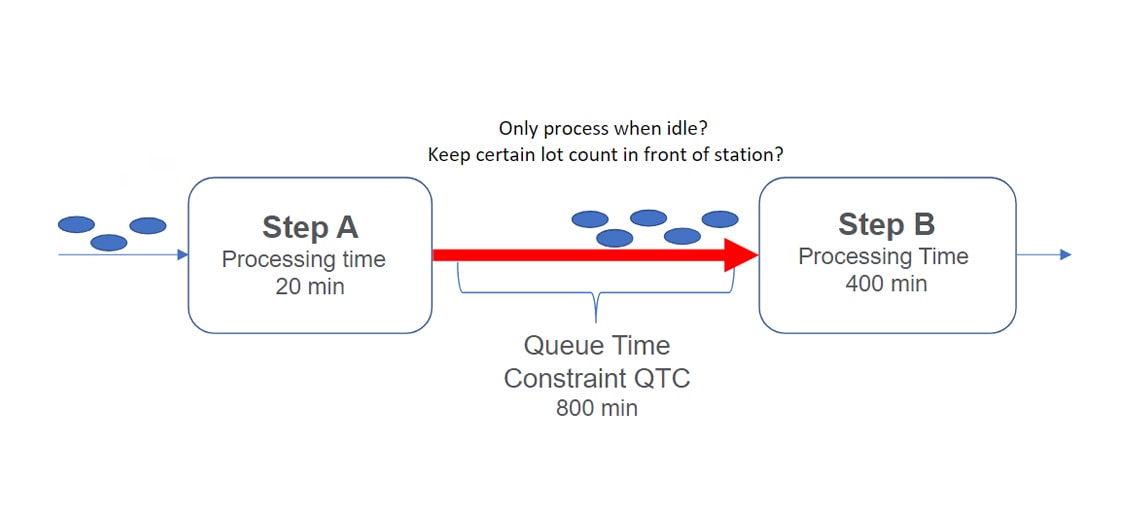
この例では、QTCの下でロットをいつリリースすべきかをRLアルゴリズムに学習させることが目標です。アルゴリズムは、キュー時間違反を最小化しスループットを最大化することを報酬とみなし、その結果につながる行動を継続的に取ろうとします。一方、ペナルティはキュー時間違反となるため、違反を引き起こす行動を避けるよう学習します。
RLの実際の応用例のひとつとして、「SmartFactory AI™ Productivity tunes dispatching rule parameters automatically, in less time(SmartFactory AI™ Productivityがディスパッチルールのパラメーターを短時間で自動的に調整する)」をご覧ください。
以下に、現実世界のデータをこのように活用することで得られる利点の一部を示します。
適応性
RLは、変化の激しい環境でも適応し学習できる能力を備えています。シミュレーションに依存する手法とは異なり、RLは現実世界のデータから直接学習し、複雑で不確実な状況にも柔軟に対応できます。アルゴリズムは環境と直接やり取りし、フィードバックを活用して意思決定を改善することで、変動の多い環境でも高いパフォーマンスを発揮します。
スケジュールとディスパチングにおいて、この適応力は特に重要です。新規注文や機械の故障、その他予期せぬ事象がスケジュールと作業配分の判断に影響を与えるため、RLの迅速な対応能力は不可欠です。さらに、半導体製造では複数の機械や処理時間、依存関係を伴う複雑なワークフローが存在し、その管理は非常に難しいものです。RLはこれらのワークフローを理解し最適化する能力を持つため、最適な意思決定を実現できます。
最適な意思決定
人間の介入に頼らない自律的な意思決定は、スケジュールとディスパチングの生産性において非常に重要な役割を果たします。従来、半導体工場では機器の制約を管理し生産フローを最適化するにあたり、領域ごとに異なる複数のディスパッチルールやスケジューラに依存していました。これらのルールはたいてい複数のパラメータを含み、ユーザーが定期的に手動で調整する必要があります。
対照的に、RLはオフラインの学習環境で累積報酬を最大化することを学ぶことで、自律的な意思決定を可能にします。探索と活用を通じて、RLアルゴリズムはオンラインの生産環境で望ましい結果をもたらす最適な戦略を学習します。手動でのパラメータ調整に頼る代わりに、RLアルゴリズムはシステムの性能を自律的に適応・最適化できるようになります。これにより頻繁な手動介入が不要となり、時間・労力・コストの削減につながります。
スピード
リアルタイムのスケジューリングとディスパチングシステムは、顧客納期など時間に敏感な要件を満たす製造業務に欠かせません。リアルタイムシステムは、ボトルネックの発見、作業負荷の分散、リソースの効率的な割り当てを支援し、効率やスループットの向上につながります。RLアルゴリズムはリアルタイムで学習し、環境に応じて瞬時に意思決定を行うことができます。この特性により、変化する環境にすばやく対応し、生産性を最大化することができます。
さらに、RLは転移学習にも対応しており、あるタスクや環境で得た知識を別のタスクや環境に応用できます。この機能により、RLはこれまでの知識を活用して、より高い熟練度で作業を開始できるようになります。学習した知識を転用することで、異なるディスパチングエリアへの移行時の適応を加速することも可能です。
まとめ
RLには多くの利点があります。自律的な意思決定、リアルタイム学習機能、そして継続的な進化能力により、非常に有望な手法です。このAI手法の進化は、現実の半導体のスケジュールやディスパチングにおける複雑な課題への対応に大きな可能性をもたらします。
RLアルゴリズムを活用することで、半導体メーカーは生産リードタイムの短縮、スループットの向上、そして全体的な生産性向上を実現できます。
