
Stages of deployment

Data collection challenges
While each phase has its own challenges, preparing the substantial, high-quality data required for an accurate model during the first stage often is enough to discourage companies from continuing the process toward deploying AI.
Collecting and formatting diverse data required for deep learning is often expensive in both time and money, which is sometimes infeasible for smaller companies.
Even if a manufacturer has the resources required to collect large amounts of data, historical data is often inadequate due to an evolving environment. For example, tools and process steps are constantly adapting to uncertainties found in supply chains, labor limitations, or change in part types.
Evolving scenarios (i.e., adding more time constraint steps) in semiconductor manufacturing are especially common as technology nodes progress. Consequently, these rapid changes do not allow time for a diverse, historical dataset to develop to train models.
The simulation solution
However, what if there was a way to get more quality data? What if AI could be explored on business essential use cases without the resource limitations of technology advancements?
With simulation, you can answer these ‘what-ifs’! You can model various scenarios and generate synthetic data to use in AI training. Projects can be accelerated without the cost of cleaning raw datasets and in significantly less time than it takes to collect a sufficient amount of data. Quantifying the impact of changes in a simulated environment prior to production implementation is also key to avoiding unnecessary, costly risks. Furthermore, training models on rich datasets develop more robust, resilient models. Evaluating on-edge cases or other diverse scenarios that seldom occur in historical data increases generalization abilities of models, which improves accuracy overall.
Requirements for an acceptable simulation model
Simulation requires many details for an accurate semiconductor manufacturing replication. Not only must simulations replicate various scenarios in a semiconductor factory environment, but they also need to have the ability to replicate dispatching and scheduling rule behavior found in a production system.
Use cases: where simulation can support AI in smart manufacturing
There are multiple scenarios where simulation plays a key role. For starters, Reinforcement Learning (RL) is growing in popularity and simulation can play a vital role in this architecture. RL involves an agent, a computer program or an intelligent system, attempting to take actions in an environment to change its state for maximum manufacturing and productivity. Here, an accurate, very detailed simulation model can act as the environment where the agent’s actions can be observed and changed. For example, a simulated environment can support an agent in learning when to release lots in a queue-time constraint scenario. Figure 2 below shows an RL framework that includes a simulator environment.
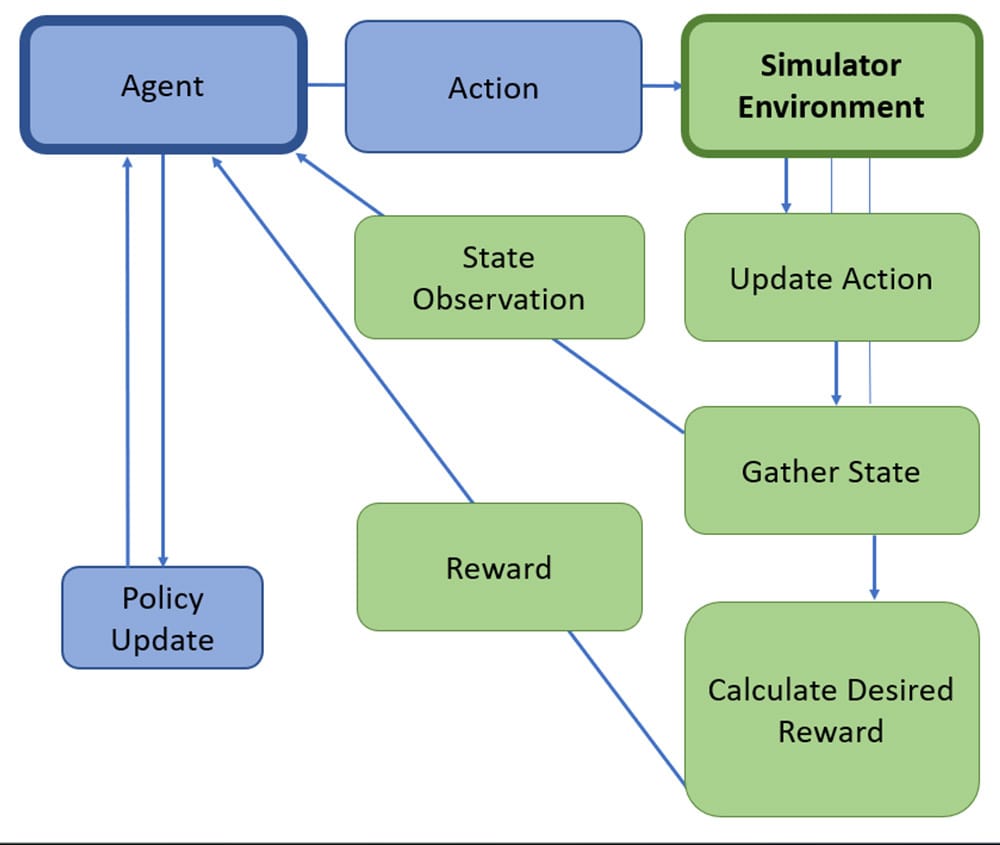
Another great example is utilizing simulation in a machine learning (ML) framework, such as predicting cycle time. Simulation allows models to be trained on a rich, multi-year dataset, which aids prediction accuracy. Operational efficiency gains are then possible as planners are given the opportunity, in a non-production, simulated environment, to test and validate changes such as updating dispatching and scheduling parameters required for late lot predictions. Just as in the RL example above, simulation can find key performance indicator (KPI) differences by evaluating ML or RL models versus existing dispatching rules or scheduling models. This provides the powerful opportunity to compare those differences.
Conclusion
Quick, scalable run times and flexibility to accommodate various planning horizons are also necessary. From simulating a short-term planning situation (i.e., two-day run to illustrate a tool down scenario) to a larger simulation model to represent a long-term planning example (i.e., one year run to demonstrate the impact of adding new equipment), end users will always want a reasonable run time with results in minutes.
Together, simulation and AI can create a productivity solution that enables real operational efficiency gains. A fast, flexible, scalable, and very accurate simulation aspect provides the opportunity to support AI solutions for current dispatching and scheduling dilemmas. From predicting lot cycle time to optimizing dispatching parameter values and scheduling constraints, SmartFactory AI™ Productivity is rapidly accelerating AI innovations into a reality!
FAQs
Why is data preparation for AI considered a challenge in semiconductor manufacturing?
Data preparation for AI can be expensive in terms of time and resources, making it a barrier, especially for smaller companies. Historical data may also be insufficient due to evolving environments.
How does simulation help overcome data collection challenges for AI deployment?
Simulation allows for the creation of synthetic data, eliminating the need for extensive data cleaning. It provides an efficient way to generate diverse and high-quality data for AI training.
What are some practical benefits of using simulation in AI deployment?
What role does simulation play in scenarios like Reinforcement Learning (RL) and Machine Learning (ML) in semiconductor manufacturing?
Simulation plays a crucial role in RL by providing a detailed environment for agents to learn and make decisions. In ML, it allows models to be trained on rich datasets, leading to operational efficiency gains and KPI comparisons.

