
In our first installment of the data scientist conundrum series for modeling we described typical issues of the first step in the modeling effort and suggested SmartFactory Rx® as a route to minimize those challenges [https://appliedsmartfactory.com/blog/the-data-scientist-conundrum/]. Indeed the first step, as depicted in Figure 1, consumes most of the data scientist’s time with estimates ranging from 65% to 95% for systems not previously modeled. A good rule of thumb is that 75%-80% of the data scientist’s time is spent on the data aggregation, cleaning, and preprocessing tasks.
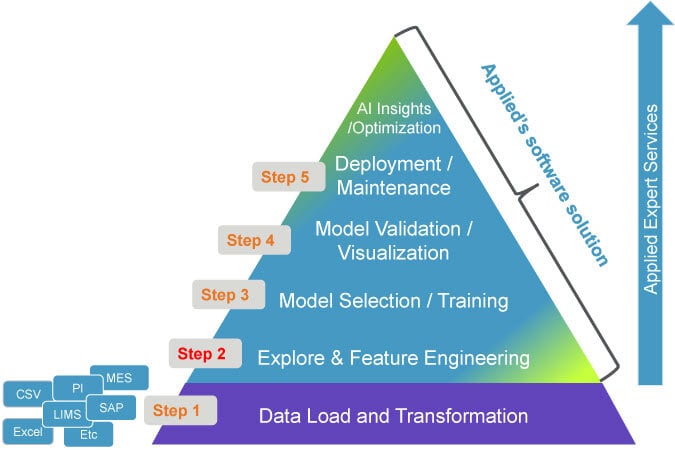
Here we will look at the second step, Explore & Feature Engineering, of physical/chemical system modeling. The traditional modeling approach has been based on first principals modeling meaning using transport phenomena equations, relevant chemical reactions equilibria, plasma equations etc. for the manufacturing line applications that require near real-time decision-making. This in turn makes it prohibitively expensive as it requires large numbers of sensors, sampling/metrology, and a significant computational power to provide timely results. For this reason, statistical modeling was invented and has proved highly beneficial across many industries. In the last century univariate (UVA) and multivariate (MVA) techniques have been employed to monitor production line efficiency, anomaly detection as well as maintenance needs. The applicability of UVA and MVA models has been significantly augmented when stochastic and Machine Learning techniques have been added to the available “toolbox” for the modelers.
We’ve been assisting our customers in monitoring their development and manufacturing lines in Display, Solar, Semiconductor and recently Pharmaceutical and other Process Industries. The common request from our customers has been usability and flexibility as well as accuracy. To meet the customers’ expectations, we combined the simplicity of statistical methods coupled with the accuracy of a first principles approach. This provides our customers with the ability to create “hybrid” models – models based not only on statistics but also on the equipment design equations whether these are flow, diffusion, heat transfer, reaction equilibria or other.
The SmartFactory Rx framework makes this possible for our Pharma and Process Industries customers. The user can employ a variety of statistical quantities (in a UVA or MVA model) to compare process parameters in real time as well as monitor their relationships through a user defined equation. Thus, the user can effortlessly identify the key features to monitor for the specific process and equipment.
A key point here is the different behavior of process equipment that adds to the process variability. By using statistical methods, that include MVA and ML methods, SmartFactory Rx can tackle this different equipment behavior, especially when they are on a different maintenance cycle, efficiently with a lower computational cost.
Added to the above is the ability for the users to write their own ML model using python, a feature that is attractive for the code savvy customers that recognize that our SmartFactory Rx solution provides a very flexible infrastructure to build “hybrid” models (statistical and first principal) to monitor their pharmaceutical or other process manufacturing lines.
To learn more about our offering to aid Pharma Data Scientists

