
The current statistical method of predicting lot cycle time is, on average, only 70 percent accurate—not a reliable level of accuracy for a busy fab looking to increase productivity. Ultimately, fab teams spend a significant amount of time each day reviewing prediction data and developing new, accurate predictions because the statistical model cannot represent real-time dynamics in the fab. This points to a need for a faster, easier, and more accurate solution for predicting lot cycle time in 14-day increments. In a recent customer application, SmartFactory AI™ Productivity and Engineered Works® were proven to improve fab out prediction accuracy to 85 percent.
Through some experimental studies, we determined the most appropriate ML model for this customer’s needs was a gradient boosted tree-based machine learning model, particularly the Light Gradient Boosted Machine implementation. Widely used in the industry, this was particularly suitable because this framework is used to make predictions in tabular data, has strong generalization property on unseen data, and is robust against noise.
Using SmartFactory AI™ Productivity, the ML model was trained on the previous 24 months’ fab out data. For the feature calculation, we defined several features that can represent the lot flow and fab behavior, such as station statistics and WIP (work in process) features which are calculated daily by lot priority and by the steps of each route or part. A Clickhouse database was used to store feature data.
The ML model was built and located on top of the current working systems, so the ML module and the current RTD or scheduling solution collaborate and communicate with each other. The ML model has been trained to run based on schedules including hourly, daily or by shift, and has learned the lot flow and current fab behavior from any one step to the final. It will create one model per step to predict cycle time at the final step. For example, if there is a lot at step A and 12 steps are remaining until fab out, then 12 models will be generated, one model per step pair to predict the cycle time until the final step. Each model will be trained on the historical feature data, WIP profile from the current step to the final step, utilization, tool availability, and lot priority. These models are saved to pickle files on disk, and all are aggregated into one main pickle file for Formatter. These can be deployed to production.
You can see the details of deployment and the results in Figure 1.
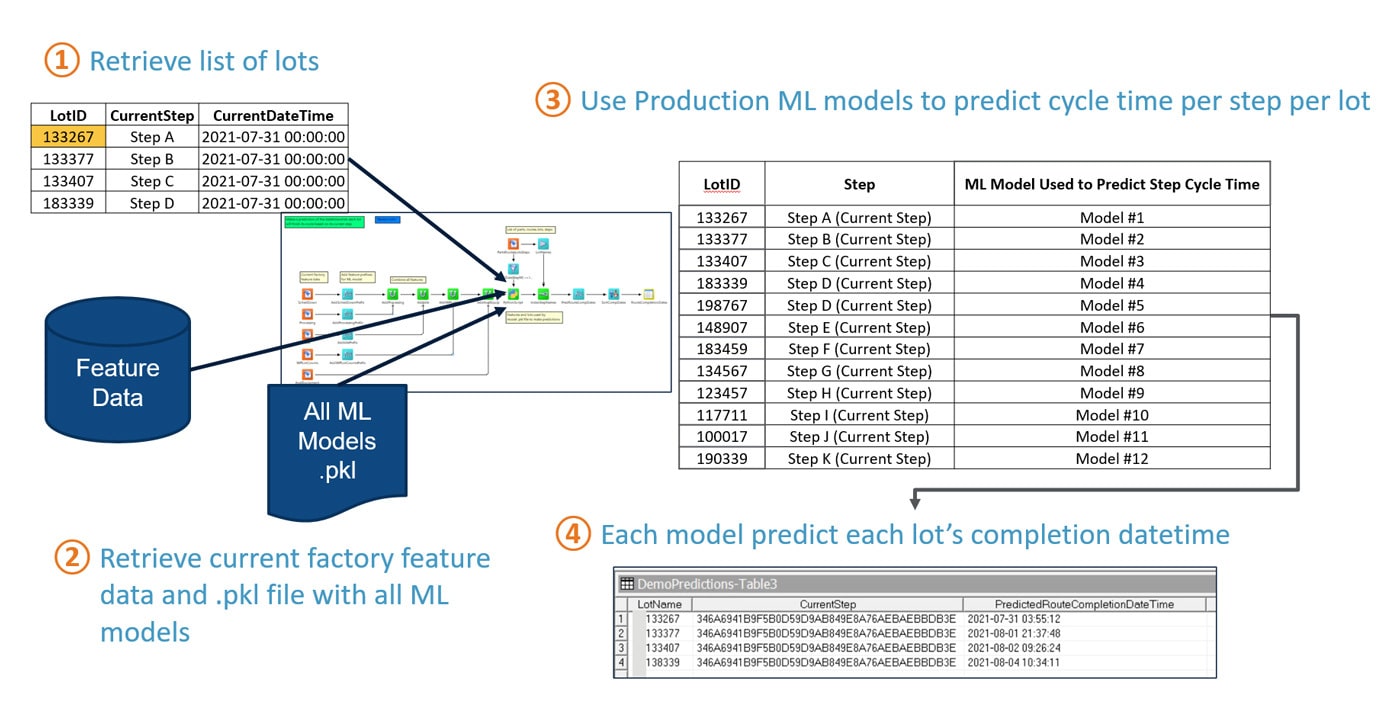
When the current RTD or scheduling solution system needs a certain prediction, it will refer to those the ML module has made. The ML model automatically retrains based on conditions not covered in its past training data and the predictions are modified and become more accurate as a result.
With an accurate fab out prediction model, fabs can better determine reasons for late lots and improve order to delivery, for example by changing dispatching rule parameters to expedite the late lots.
The ML model developed for the customer was evaluated based on test data set after the training was completed. Metrics defined for model evaluation and accuracy included as key performance indicators: Root Mean Squared Error (RMSE) and Mean Absolute Error (MAE). We defined the accuracy metric as 1-Mean Absolute percentage error, meaning the average of each lot’s prediction accuracy. Our accuracy comparison showed the ML model had 5 to 13% better results than baseline model. This approximately 10% accuracy increase could lead to a 2% on time delivery (OTD) increase and 2% inventory maintenance cost reductions.

