
Typically, semiconductor manufacturing facilities implement 8 to 10 area-specific dispatching rules and 4 to 5 area-specific schedulers to improve equipment bottlenecks. The algorithms tend to have 5 to 10 parameters each, which can be configured for optimizing the performance of the system. The users tend to change these parameters several times per week.
Because it’s difficult to recreate complex logic in an offline environment, manufacturers conduct soft runs in the production environment to analyze the impact of dispatching and scheduling algorithms. Running this analyses in production, can result in downtime or negatively impact the factory moves for the duration of the testing period.
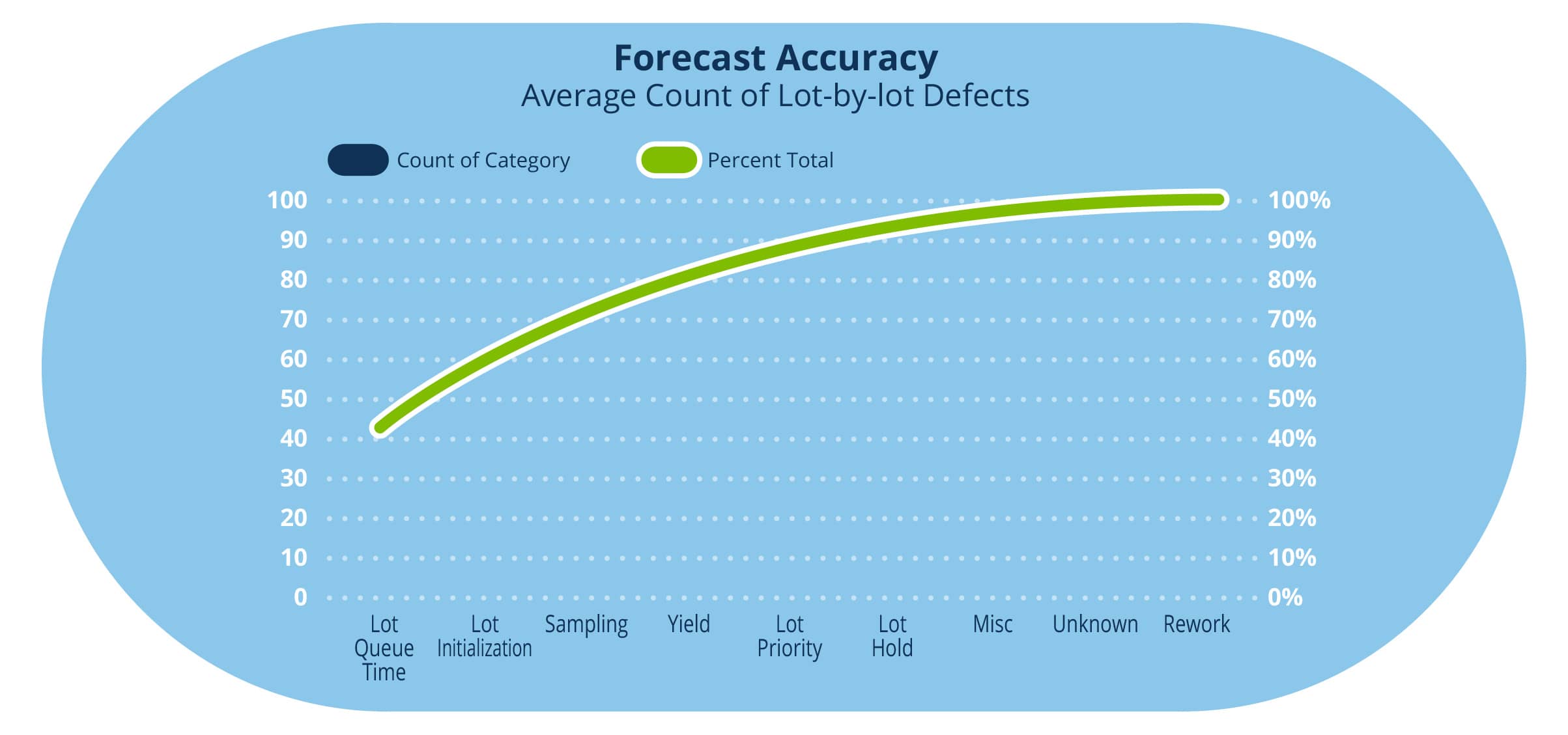
Companies use dynamic simulation capabilities to forecast weekly output from factories, identify bottlenecks, plan for equipment downtime, and set move target goals for areas. They are using simple basic dispatching rules, instead of the rules used in production and this results in generating several gaps between the production and simulation outputs. Figure 1[1] below summarizes the typical gaps observed in the online simulation at the lot-level. In this case, a gap represents the delta between an actual lot’s step count and a simulated lot’s step count, and that delta is greater than an allowable threshold over a period.
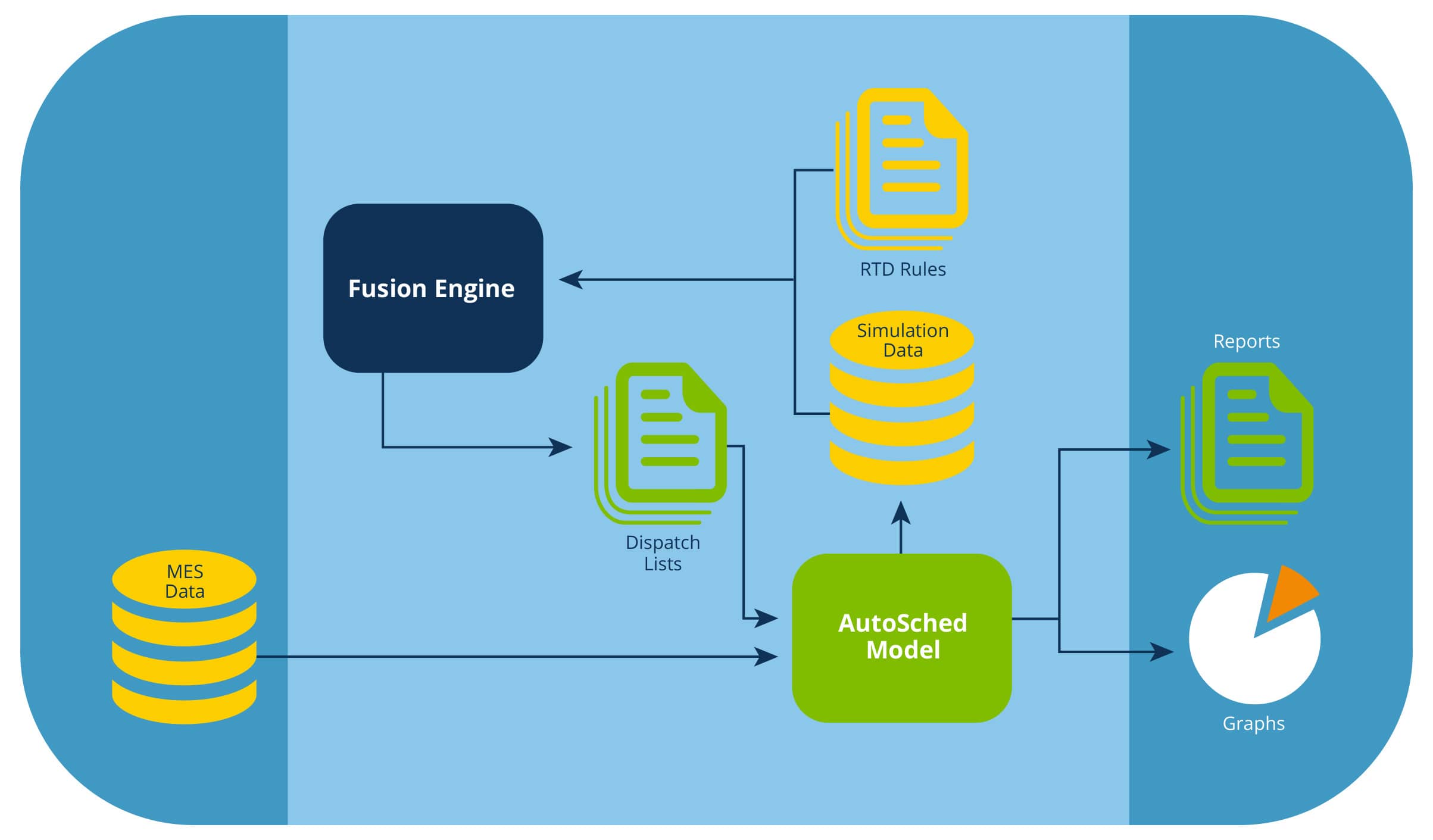
To address these challenges, Applied’s APF Fusion module integrates dispatching and scheduling algorithms developed using Applied’ s APF Real-Time Dispatcher® (RTD) rules in production within our SmartFactory AutoSched® simulation model.
Our APF Fusion module enables manufacturers to reuse the production dispatching rules without requiring the engineers to use customizations in the AutoSched simulation module. Figure 2 shows the high-level architecture for APF Fusion capabilities.
The Fusion engine acts as a dispatcher for AutoSched. The key difference between Fusion and an APF dispatcher is that Fusion has been designed to use Autosched’s factory data in memory rather than data from a repository.
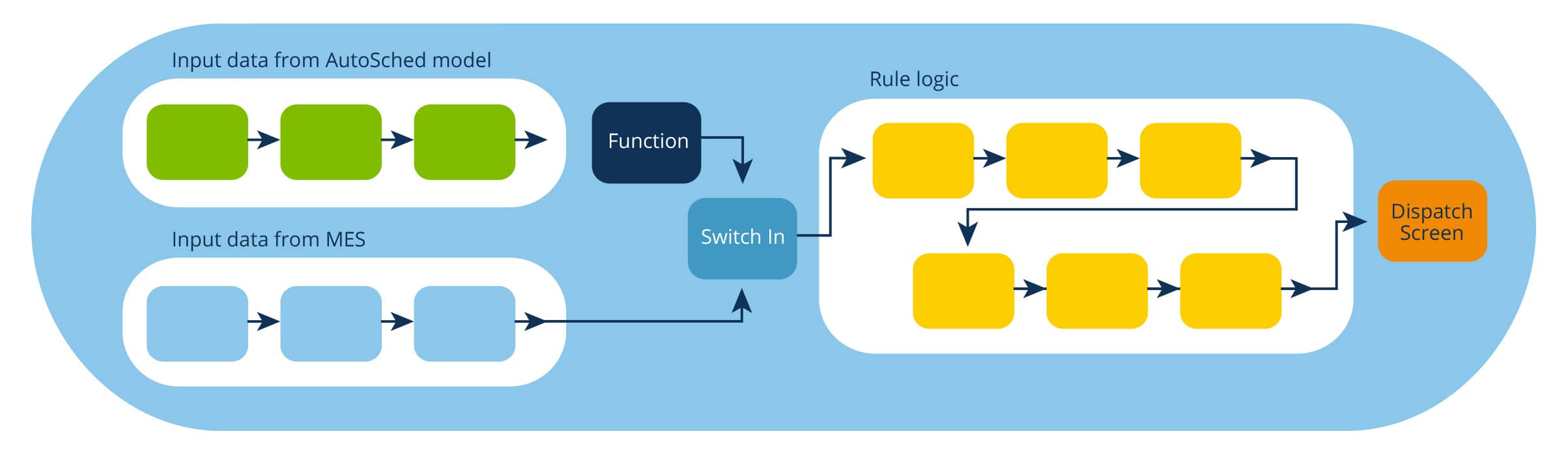
- You need to create separate “branches” of blocks that read input data from the appropriate data source. Then, use a Switch-in block to toggle and identify the branch of input data to execute when the rule runs. The branch that reads from the AutoSched model (if the rule is running in simulation) or the MES (if the rule is running in production)
- Because the AutoSched model schema is different than the MES data schema, the rule uses a function block to rename data elements from the AutoSched model and performs type conversions (if necessary) so that their names and types match corresponding data elements from the MES. The rule’s logic then performs the same operations, using the same input parameters, regardless of the data’s source.
The benefit of using the integrated dispatching and simulation solution is it allows manufacturers to proactively work within the production system environment with actual data as part of a continuous improvement activity.
Benefits of our SmartFactory Integrated Dispatching and Simulation Solution
- Evaluate dispatch rule /scheduling policy changes without impacting production
- Determine the impact of KPI due to line down and other scenarios
- Increased confidence and reduced risk to production due to new changes
- Improve cost of ownership
- No need to use C++ extensions to model dispatching and scheduling policies
- Share rules between production and simulation
- Share KPI reports between production and simulation
- Reduce rule complexity by eliminating non-essential logic
- Get RTD training resources online, enabling manufacturers to experiment in a safe sandbox

