In today’s fabs, it has become increasingly difficult and time-consuming to integrate and harmonize the data coming from diverse CIM (computer-integrated manufacturing) applications. In fact, this is now a major stumbling block to the rapid deployment of these systems and, hence, to the ability of a fab to quickly achieve targeted productivity.
All modern fabs face this issue, but it is especially acute for (1) new companies building semiconductor factories with limited prior experience and without access to skilled resources for rapid deployment; (2) Outsourced Semiconductor Assembly and Test (OSAT) or Assembly, Test and Packaging (ATP) companies, which are becoming more wafer fab-like in their operations; and (3) companies affected by ongoing industry consolidation.
The problem stems from the fact that manufacturers use a broad array of decision-support and manufacturing execution systems (MES) to meet customer commitments. Typical CIM applications include planning, scheduling, dispatching, automation and reporting. The interactions of these systems are described in Figure 1.
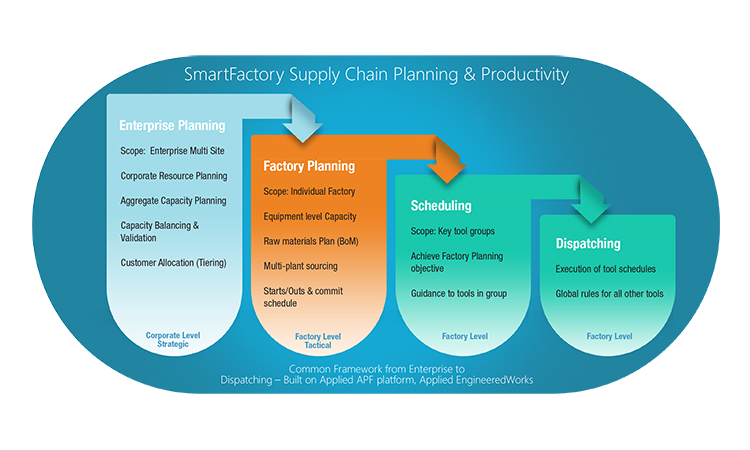
These systems rely on massive amounts of data from different CIM components, and the data needs are continuing to grow as device geometries shrink and as fabs ramp new technologies.
The data included in these systems relates to orders, products, process steps, equipment and operators. For example, order-related data might include product names, due dates, customer names, quantity, bill of materials, etc. Data related to processing steps might include step names, sequencing, equipment certifications, processing times, sampling and other relevant information.
Equipment-related information, meanwhile, might include equipment names/types, location, setups, batch sizes and preventive maintenance (PM) schedules/durations. In addition, it also might include auxiliary resources such as reticles, probe cards etc. Operator-related data such as certification and shift schedules also may be required.
In general, the data described above resides in different CIM components with their own integration methods and data structure models. In some cases data does not exist, is incomplete, or is being manually maintained on someone’s laptop.
Moreover, additional data from Advanced Process Control (APC) systems (run-to-run, fault detection and classification, etc.) increasingly is being used to make dispatching and scheduling decisions on the factory floor [1]. Automated material-handling (AMHS) data [2] also needs to be included in the decision-making process because today 300mm factories and 200mm and ATP factories are leveraging the use of Automated Guided Vehicles (AGVs) and robots to improve production performance [3].
Also, mobile applications [4] are being used to drive productivity improvements, and they may require real-time data from different factory sources.
Furthermore, the ITRS roadmap [5] notes that holistic factory scheduling plays a key role in improving equipment utilization, cycle time and on-time delivery. Making this possible means there is a need to integrate even more data. The roadmap defines the need for a real-time predictive scheduling tool that would incorporate predictive maintenance (PdM), PM scheduling, equipment health monitoring [EHM] and resource scheduling data.
Typically, the cohesive integration of all these systems is one of the most time-consuming aspects of their deployment. It can take anywhere from 6- to 12 months because no standard data model is defined. A considerable amount of time also must be spent validating and cleansing the data.
In the past, fabs typically addressed these needs by copy-exact methods, and they had a lot of skilled people available to ramp these systems to optimal usage.
This may no longer be the case, and so new models must be defined to maintain and automate the data. Some efforts have been made to develop a detailed data model and framework for semiconductor fabs [6], and industry and academic institutions have expressed the need to standardize the data model for decision-support systems. SEMATECH’s Modeling Data Standards [7] is one example.
But there has been little or no progress.
To address this gap, Applied Materials is developing a common data model using the Extract, Transform and Load (ETL) capabilities modules from Applied’s APF (Advanced Productivity Platform) software environment.
In addition to a common data model, pre-engineered productivity tools are also being developed to help customers achieve rapid system deployment and achieve productivity gains faster.
REFERENCES
[1] Marcel Stehli, Daniel Zschabitz, Thomas Jaehnig, “Bridging the Gap – Integrating APC Constraints and WIP Flow Optimization to Enhance Automated Decision-Making in Semiconductor Manufacturing”, ASMC 2015
[2] Christian Hammel, Robert Schmaler, Thorsten Schmidt, Joerg Lubke, Matthias Schops, Ulrich Horn, Marcin Mosinski, “Empowering Existing Automated Material Handling Systems to Rising Requirements”, ASMC 2016
[3] Didier Chavet, Shekar Krishnaswamy, “Factory Automation is Key to Sustainable Manufacturing at Western Digital at Shanghai Assembly and Test facility”, Nanochip-Fab-Solutions/december-2016
[4] Didier Chavet, Shekar Krishnaswamy, “Mobile Applications to Enhance Manufacturing Productivity in Advanced Packaging”, IWLPC (Wafer-Level Packaging) 2014 conference proceedings
[5] International Technology Roadmap for Semiconductors 2.0, 2015 edition Factory Integration
[6] Heshan Li, Jose A. Ramirez-Hernandez, Emmanuel Fernandez, Charles R. McLean and Swee Leong, “A Framework for Standard Modular Simulation in Semiconductor Wafer Fabrication Facilities”, Proceedings of the 2005 winter simulation conference
[7] SEMATECH, “Modeling data standards, version 1.0”, Technical Report, SEMATCH Inc., Austin, TX, 1997

